Topic:
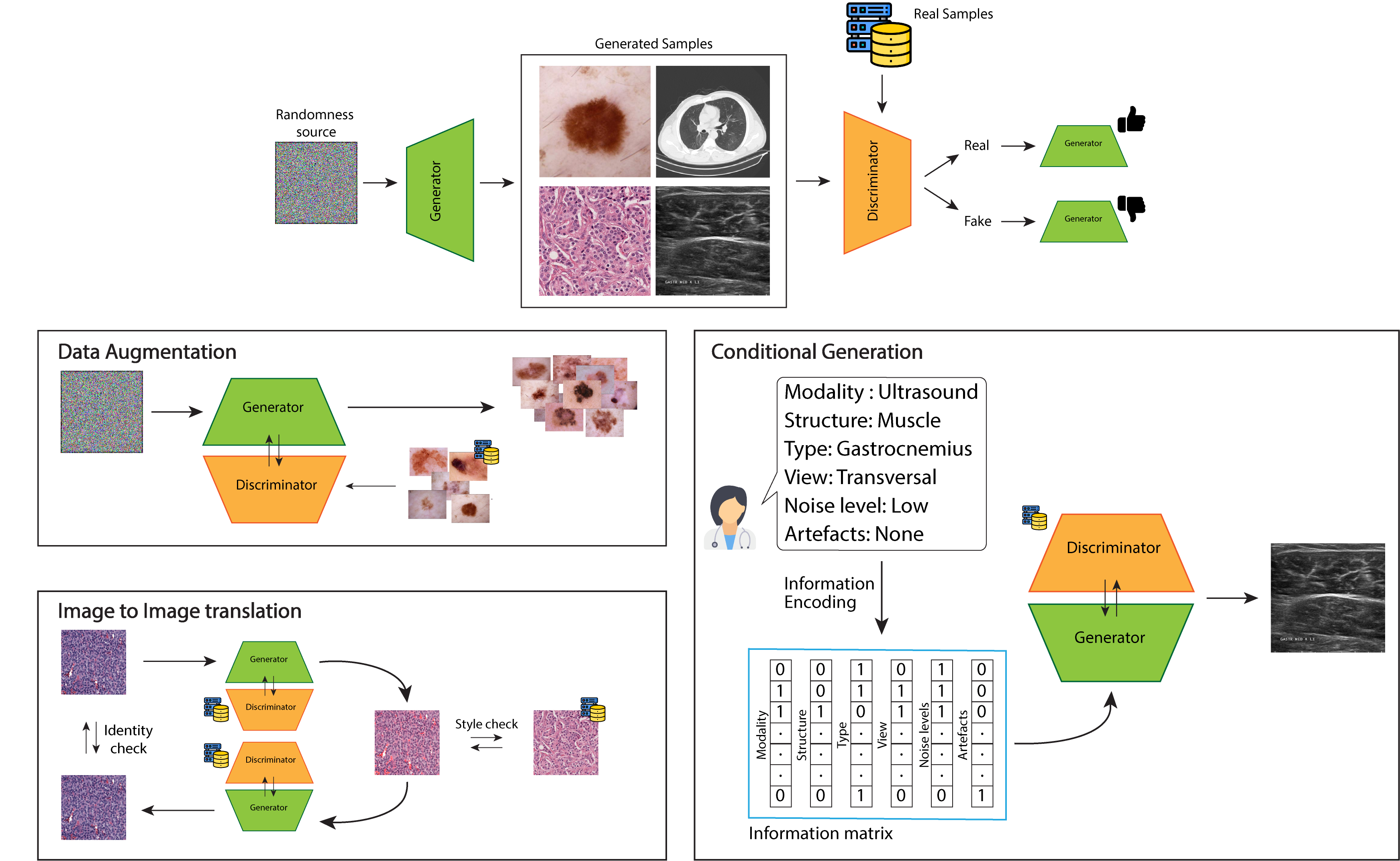
In the deep learning era, having access to a large quantity of data is fundamental to build systems with the desired performances and reliability. The medical field is not an exception. Moreover, the added challenges of dealing with sensitive data, following GDPR regulations, and the requirement of highly trained experts to label such data, make good quality data not always readily available as a resource. A very promising solution is using a Generative Adversarial Network (GAN) that, through the competition of two or more neural networks, learns the statistical features of the real data and generates fake data which are interchangeable with real data, while maintaining the variability we observe in the natural world.
New data can be generated by a network from a source of randomness, typically a vector of random noise or a map of the structures we want to observe in an image, or by translating an image from a domain to another semantically similar domain. As an example, we can use a GAN to translate an MRI image to a CT domain, or to change the colorization of a biopsy to highlight different structures using the same sample.
Synthetic data generation can have a disruptive impact in the medical imaging field, allowing the use of deep learning where data is scarce, or reducing the bias present in unbalanced datasets, improving existing computer-aided-diagnosis (CAD) systems or helping create new ones. It could also improve the training of operators granting them access to wider and more precise data to guide their development.